请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:LP-AM243 主题中讨论的其他器件:AM2434
您好专家、
我修改 了 GPIO_LED_BLINK 演示代码、以测量将 GPIO 从高电平设置为低电平或从低电平设置为高电平的延迟。 我的代码很简单。
1、不使用器件驱动程序直接操控寄存器。
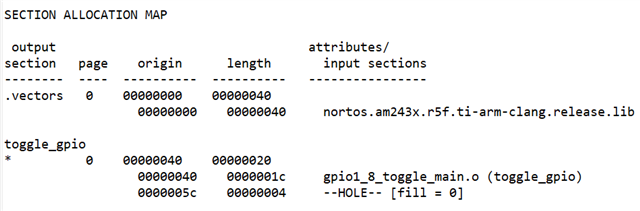
2. 通过添加一个可无限执行切换的函数将代码放入 TCMA。
void __attribute__((section ("GPIO_toggle")) toggle_GPIO1_8 (void)
{
while (1)
{
* GPIO1_8_SET_ADDRESS = GPIO1_8_MASK;
* GPIO1_8_CLEAR_ADDRESS = GPIO1_8_MASK;
}
}
链接器命令文件
第{
GPIO_toggle:palign (8)
}> R5F_TCMA
3.将构建环境设置为释放模式,并将优化级别更改为快速。
4.编程到器件并进行测量。
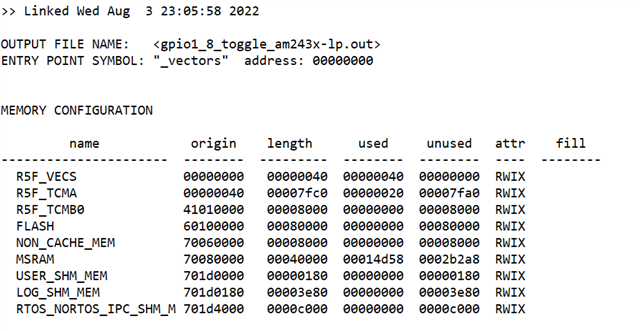
附件是我的项目文件。 我使用 SDK 8.3
e2e.ti.com/.../gpio1_5F00_8_5F00_toggle_5F00_am243x_2D00_lp.zip
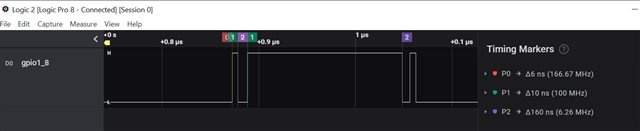
以下是测量结果。

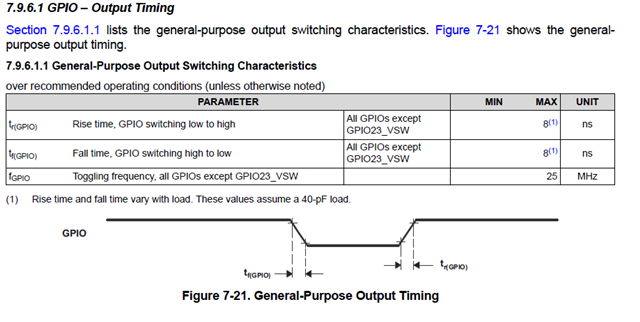
根据测量结果、切换 GPIO 的延迟为184ns、但来自数据表。

最小脉冲可以是3.6ns + 8ns * 0.975 FICLK = 500MHz /4 =125MHz = 8ns。
间隙很大、我是否可以通过使用 GPIO 模块切换 GPIO 来知道这个典型值?
我们如何获得数据表结果?
此致
Andre