主题中讨论的其他器件:TMDSCNCD28388D、 C2000WARE
你好
我在 CPU1项目中编写了一个名为 HandleCmToCpu1IpcRequests 的函数、该函数通过以下方式将来自 CM->CPU1消息 RAM 的数据复制到结构中:
memcpy (&s_CanTelegramReceivedFromMaster、(const void *) ipcAddr、(size_t) sizeof (s_CanTelegramReceivedFromMaster)
在不久的将来、我必须从 RAM 运行函数 HandleCmToCpu1IpcRequests 和从该函数调用的所有其他函数。 这是必需的、因为 HandleCmToCpu1IpcRequests 可从 IRQ 中调用、而 CPU1的闪存可能正在擦除扇区的过程中。 因此、我首先尝试通过链接器命令文件将 memcpy 函数本身移动到 RAM、例如对于.TI.ramfunc 段:
--library=rts2800_fpu64_eabi.lib (.text)
但这显然不是一个好主意、因为我收到了链接器警告、并且固件不再工作:
"./2838x_flash_lnk_cpu1.cmd"、行92:警告#10068-D:无匹配段
警告#10278-D:为".text:rts2800_fpu64_eabi.lib 段指定了加载放置 "。 本节包含链接器生成的复制表和 C/C++自动初始化所需的解压缩例程。 必须确保在执行 C/C++引导代码之前将此段复制到运行地址、或使用单个分配说明符(例如、">"存储器")进行放置。
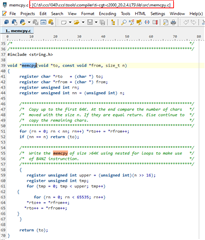
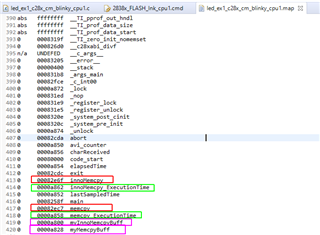
之后、我将 memcpy 函数从 C:\ti\ccs1040\ccs\tools\compiler\ti-cgt-C2000-20.2.4.LTS \lib\src\memcpy.c 复制到我的项目中、将该函数重命名为 innoMemcpy 并将其移动到 RAM 中:
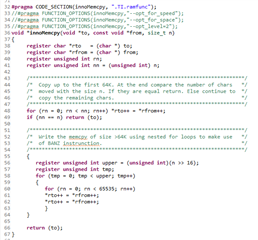
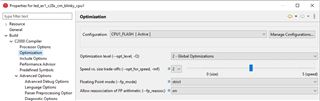
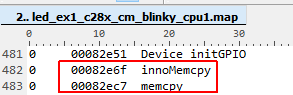
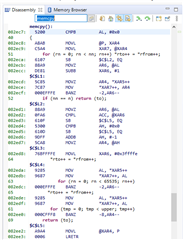
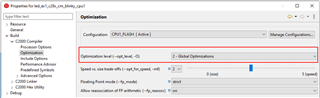
我现在通过 CPU 定时器1测量了 HandleCmToCpu1IpcRequests 函数的执行时间。 无论我为 innoMemcpy 使用哪种其他 pragma、如-opt_for_speed 或 opt_level=2 (请参阅上图)、innoMemcpy 函数的速度始终是 rts2800_fpu64_eabi.lib 库 memcpy 的两倍。 因此、在下图中、第一行始终比第二行的因子2更快。
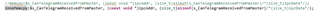
是否有什么想法会导致执行时间的差异? 如何使函数 innoMemcpy 的速度与 memcpy 一样快?
谢谢、
Inno