请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:TMS320F280025 由于处理器带宽限制、我们正在进行代码优化。 我们针对处理器设置和优化进行了以下设置:

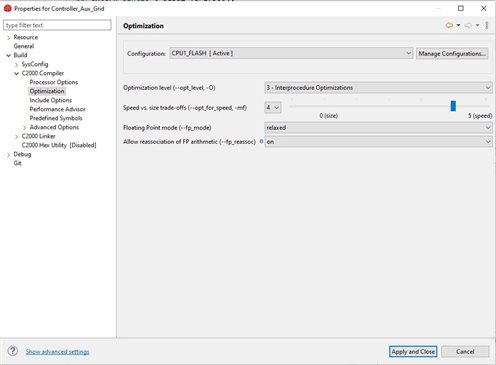
请告诉我们上述设置是否正常、或者我们是否可以进一步提高代码的执行速度?
我们希望 TMU 指令应用于正弦等三角函数 为了确认我们的设置是正确的、我们查看了代码的汇编列表以查看是否存在 TMU 指令。 以下是一个列表:
270 TS= sin (FS);
08467e:764886DF LCR __relaxed_sinf
084680:E2030052 MOV32 *-SP[18]、R0H
TS 和 FS 都是浮点数。 编译器正在使用__relaxed_sinf 指令。 我们期待的是 SINPUF32。 请解释这一区别。