

Other Parts Discussed in Thread: F28M35H52C
请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:F28M35H52C 您好!
我正在使用我们定制设计的应用硬件上安装的 F28M35H52C Concerto 器件。 这是一种新设计、我们在没有任何代码加载到器件的情况下执行了首次加电测试、因此 Concerto 器件处于其初始的现成状态。 在施加所有电源电压且没有过载迹象的情况下、我开始检查 XRS/ARS 复位引脚上的复位信号。 这些引脚按照器件文档的建议连接在一起。 我发现这些引脚上的意外脉冲仅在器件尝试引导至闪存时出现。 如果引导模式更改为串行接口、这些脉冲将消失并且 nXRS = 1、这是预期的。
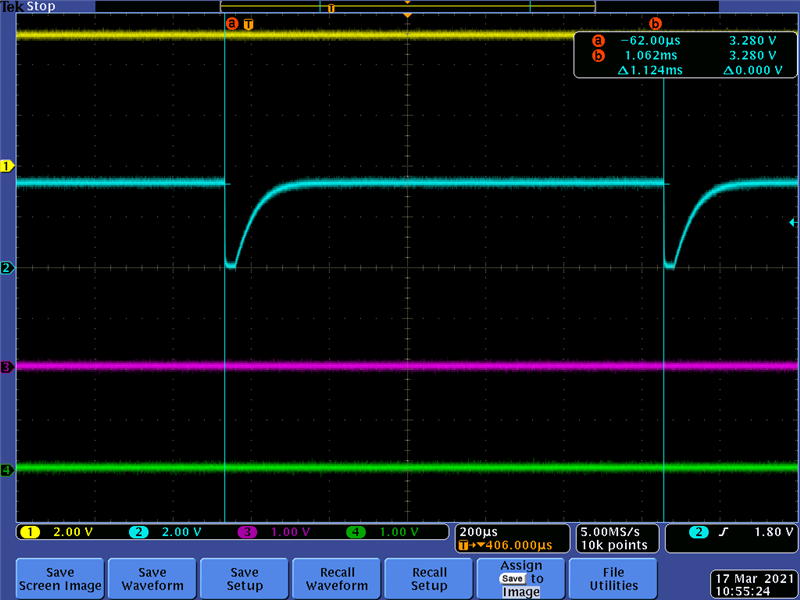
我认为这些复位脉冲由其中一个看门狗计时器触发。 在检查 TRM 后、我发现 WDT1和 WDT0计时器默认处于禁用状态、因此我认为复位是由 NMI WDT 触发的。 但这里是我产生困惑的地方。
我们应用中的 X1时钟为20MHz、因此时钟周期为50ns。 根据上面提供的 nXRS 波形、复位脉冲周期为1.124ms。 但是、鉴于 NMI WDT 是16位计数器、我预计周期为50ns * 2^16 = 3.2768ms、这大约是观测周期的3倍。 我不确定是需要1个还是2个 NMI WDT 周期来触发系统复位、但观察到的周期只是单个周期的几分之一。
我的问题如下。
Q1:观察到的 nXRS 脉冲是否正确由 NMI WDT 计时器引起? 如果不是、可能的来源是什么?
Q2:如果这些脉冲确实是由 NMI 看门狗引起的、那么为什么预期周期值和观测周期值之间存在差异?
谢谢、
Michael

