

请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:TMS320F280039 工具与软件:
编译器版本:TI v22.6.0.LTS
当我编写一个算法时、我发现在打开编译器的 O2水平优化后、控制器的系数生成不正确。 所以我编写了以下代码进行测试、其中输入参数 w 为1:
struct TEST_STRUCT
{
float f1;
float f2;
};
volatile struct TEST_STRUCT TEST[5];
void TEST_FCN(float w)
{
Uint16 Index;
float w_temp;
for( Index = 5 ; Index > 0 ; Index-- )
{
w_temp = w * ( Index * 2 - 1 );
TEST[Index - 1].f1 = w_temp;
}
}
开启 O2后生成的汇编代码如下:
MOVB XAR6,#4 ; [CPU_ALU]
MOVL XAR4,#||TEST||+16 ; [CPU_ARAU]
MOVIZ R3H,#16656 ; [CPU_FPU]
.dwpsn file "../main.c",line 22,column 22,is_stmt,isa 0
RPTB ||$C$L2||,AR6 ; [CPU_ALU] |22|
; repeat block starts ; []
||$C$L1||:
MOVIZ R2H,#18303 ; [CPU_FPU] |22|
.dwpsn file "../main.c",line 25,column 9,is_stmt,isa 0
MPYF32 R1H,R0H,R3H ; [CPU_FPU] |25|
.dwpsn file "../main.c",line 22,column 22,is_stmt,isa 0
MOVXI R2H,#65024 ; [CPU_FPU] |22|
ADDF32 R3H,R3H,R2H ; [CPU_FPU] |22|
|| MOV32 *+XAR4[0],R1H ; [CPU_FPU] |25|
SUBB XAR4,#4 ; [CPU_ALU] |22|
; repeat block ends ; []
||$C$L2||:
$C$DW$11 .dwtag DW_TAG_TI_branch
.dwattr $C$DW$11, DW_AT_low_pc(0x00)
.dwattr $C$DW$11, DW_AT_TI_return
LRETR ; [CPU_ALU]
; return occurs ; []
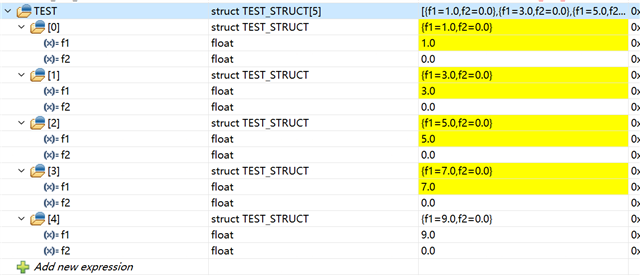
问题在于(Index * 2 - 1)的优化:编译器将(Index * 2 - 1)修复到 R3H 寄存器、以便每个周期从 R3H 减去2。 由于 Index 被声明为 UINT16无符号整数类型、因此编译器为 R2H 分配一个0x477ffe00 (65534)的值、并希望通过 R3H=R2H+R3H 执行等效的减法。 但是、RxH 是浮点寄存器、编译器只能调用 ADDF32来执行浮点加法、从而导致错误的结果:

如果我将 Index 声明为 int16、则编译的汇编代码是正确的、结果是正确的:
MOVB XAR6,#4 ; [CPU_ALU]
MOVL XAR4,#||TEST||+16 ; [CPU_ARAU]
MOVIZ R1H,#16656 ; [CPU_FPU]
.dwpsn file "../main.c",line 21,column 22,is_stmt,isa 0
RPTB ||$C$L2||,AR6 ; [CPU_ALU] |21|
; repeat block starts ; []
||$C$L1||:
.dwpsn file "../main.c",line 24,column 9,is_stmt,isa 0
MPYF32 R2H,R0H,R1H ; [CPU_FPU] |24|
.dwpsn file "../main.c",line 21,column 22,is_stmt,isa 0
ADDF32 R1H,R1H,#49152 ; [CPU_FPU] |21|
.dwpsn file "../main.c",line 24,column 9,is_stmt,isa 0
MOV32 *+XAR4[0],R2H ; [CPU_FPU] |24|
.dwpsn file "../main.c",line 21,column 22,is_stmt,isa 0
SUBB XAR4,#4 ; [CPU_ALU] |21|
NOP ; [CPU_ALU]
NOP ; [CPU_ALU]
; repeat block ends ; []
||$C$L2||:
$C$DW$11 .dwtag DW_TAG_TI_branch
.dwattr $C$DW$11, DW_AT_low_pc(0x00)
.dwattr $C$DW$11, DW_AT_TI_return
LRETR ; [CPU_ALU]
; return occurs ; []
可以看出、此时(索引* 2 - 1)固定为 R1H、生成的汇编指令为 ADDF32 R1H、R1H、#49152、即 R1H=R1H-2。
这是一个错误吗?
谢谢你。


