请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号: AM62A7
TI 团队大家好、
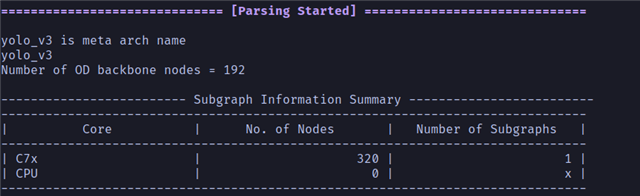
我正在部署基于 ONNX 的 地标检测模型 消息流 EdgeAI-TIDL 工具 TI NNA。
虽然该模型主要在 NNA 上运行、但我观察到了这一点 TIDL 创建了 2 个子图、而不是 1 、且推理延迟高于预期。
我想理解 这意味着什么 、 如何确认我的模型是否在 NNA 上完全运行 、和 如何替换不受支持的图层/操作 以便卸载整个模型。
平台/软件详细信息
配置 : AM62A
操作系统 :Linux
TIDL 工具 :edgeai-tidl-tools
模型 : ONNX、批次大小固定为 1