This thread has been locked.
If you have a related question, please click the "Ask a related question" button in the top right corner. The newly created question will be automatically linked to this question.
https://e2e.ti.com/support/processors-group/processors/f/processors-forum/1491248/sk-am62a-lp-problems-of-c-onnxruntime-infer
工具/软件:
仅 注入一个模型、、但它使用了340%+个 CPU 资源。
有关这些问题的代码和图片、请参阅 (+) SK-AM62A-LP:可以根据 edgeai-gst-apps /app_cpp 同时运行 CPU+npu。 -处理器论坛-处理器- TI E2E 支持论坛
您好:
TOP 和 HTop 机制考虑100%充分利用1个内核。 超过100%意味着使用了多个 CPU 内核。 在本例中、使用的是所有4个内核。
这意味着至少正在使用4个线程。 这可能是 ONNXRuntime 的默认值、默认情况下它使用 CPU 内核数
我建议检查为 ONNXRuntime 启用了多少个 CPU 线程
对于基于 CPU 的执行(尤其是有多层时)、如果器件上有4个可用、我建议将其设置为2个内核。
另外、提高流程优先级或"细度"也是值得的、以确保此任务不会被中断
BR、
Reese
e2e.ti.com/.../app_5F00_edgeai_5F00_main.cpp
你可以使用你的任何 文章模型来尝试这个程序吗、实际上 这些只是很少的 CPU 操作、即使没有后处理程序
尊敬的 Wang:
您是否会使用 perf_stats 工具来测量您的系统利用率并分享结果? 请共享两个测量值、一个在运行模型之前、另一个在模型上运行推理时。
edgeai-gst-apps 工程的一部分中的 perf_stats 工具。 以下是构建和运行的代码和说明: github.com/.../perf_stats此致、
Qutaiba
我们提供了源代码,并指出任何伪影模型都可以使用,这个问题很容易重现。 请运行它并尝试调试和解决这个问题吗? 这可能更有效、不会浪费 太多 时间。
我获取了您的文件并(经过修改)运行此文件、使用/opt/model_zoo/ONR-CL-6360-regNetx-200mf 作为进行测试的模型。 请允许我详细说明我的意见。 我已部分复制了您的错误、但未完全复制。
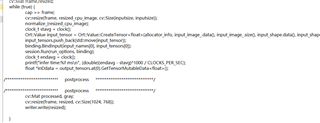
我首先在不使用来自 USB 摄像头的实时流式传输帧的情况下进行了测试、其中的核心环路如下所示:
//avoid capture, resize, new assignment for input data //cap >> frame; //cv::resize(frame, resized_cpu_image, cv::Size(inputsize, inputsize)); //input_image_2.assign(resized_cpu_image.data, resized_cpu_image.data + resized_cpu_image.total()*resized_cpu_image.channels()); //normalize_(resized_cpu_image); //modified for uint8_t, since our artifacts take uint8 in, not float. Also removes need to normalize. Ort::Value input_tensor = Ort::Value::CreateTensor<uint8_t>(allocator_info, input_image_2.data(), input_image_2.size(), input_shape.data(), input_shape.size()); input_tensors.push_back(std::move(input_tensor)); binding.BindInput(input_names[0], input_tensors[0]); clock_t stavg = clock(); session.Run(run_options, binding); clock_t endavg = clock(); printf("infer time:%f ms\n", (double)(endavg - stavg)*1000 / CLOCKS_PER_SEC); float *inDdata = output_tensors.at(0).GetTensorMutableData<float>(); /**************************** postprocess *******************************/ //no postproc /**************************** postprocess *******************************/ cv::Mat processed, gray; //Avoid resize and push to output //cv::resize(frame, resized, cv::Size(1024, 768)); //writer.write(resized);
我把时间戳移到推理调用本身之前和之后,而不是任何其他 API 调用
我无法复制极高的 CPU 负载。 我看到 CPU 平均负载约为15%(单核上没有高于25%)、当我还包括来自摄像头的输入捕获+显示输出时、平均负载会增加至40%。 我的模型无需预处理、我怀疑您的归一化会增加更多负载。 我看到测得的延迟存在差异、但这里存在一些疑问(请进一步阅读)
我注意到您使用的是 ctime" 时钟"API。 这将测量用户级时间。 当 TIDL 运行时、用户级线程正在等待从 C7x 内核返回的中断-线程被阻止、一开始不应累积用户时间。
我看到在设置中测得的"时钟"时间实际上小于 TIDL 报告的推理时间(options->debug_level=1将打印周期计数)。 这只能由 ctime API 解释、不要测量中断到达之前被阻止的时间。
我也看到了报告的运行时延迟的可变性、但我无法信任"时钟"API 来测量这里的时间。 它需要使用全局系统计时器、而不是用户时间。
请允许我在明天/未来的日子回到这里。 第一步需要使用全局计时器而不是用户时钟。
BR、Reese
返回更新
Unknown 说:我注意到您使用的是 ctime 'clock' API。 这将测量用户级时间。 当 TIDL 运行时、用户级线程正在等待从 C7x 内核返回的中断-线程被阻止、一开始不应累积用户时间。 [/报价] 我已经确认了这一点、请参阅此处的代码片段: auto begin = chrono::high_resolution_clock::now(); //new clock_t stavg = clock(); //original session.Run(run_options, binding); clock_t endavg = clock(); //original auto end = chrono::high_resolution_clock::now(); //new auto dur = end - begin; auto us = std::chrono::duration_cast<std::chrono::microseconds>(dur).count(); printf("(user time) infer time:%f ms\n", (double)(endavg - stavg)*1000 / CLOCKS_PER_SEC); printf("(system time) infer time:%ld us\n", us); float *inDdata = output_tensors.at(0).GetTensorMutableData<float>(); //must #include <chrono> 结果符合我的期望--用挂钟时间测量显示一致的运行时间(对于 regnet-200mf 模型、在4.9和5.0毫秒之间)、变化很小、而 clock ()产生的时间变化较大。 使用所有周围的预处理代码后、我仍然看到每个内核的 CPU 利用率平均高达40%。 此处的大多数多线程/过程应该是 gstreamer / CV 捕获的结果 根据我在您上一个主题中所看到的、您似乎遇到了更高的 CPU 负载和可变推理延迟。 您是否也使用 clock () API 测量了它? 我建议重新审视一下。 除此之外、您的模型可能在 CPU 上运行一些操作? 您的分辨率很小(128x128x3)、因此预处理不应该是很大的负载。 BR、 Reese
我已经确认了这一点、请参阅此处的代码片段:
auto begin = chrono::high_resolution_clock::now(); //new clock_t stavg = clock(); //original session.Run(run_options, binding); clock_t endavg = clock(); //original auto end = chrono::high_resolution_clock::now(); //new auto dur = end - begin; auto us = std::chrono::duration_cast<std::chrono::microseconds>(dur).count(); printf("(user time) infer time:%f ms\n", (double)(endavg - stavg)*1000 / CLOCKS_PER_SEC); printf("(system time) infer time:%ld us\n", us); float *inDdata = output_tensors.at(0).GetTensorMutableData<float>(); //must #include <chrono>
结果符合我的期望--用挂钟时间测量显示一致的运行时间(对于 regnet-200mf 模型、在4.9和5.0毫秒之间)、变化很小、而 clock ()产生的时间变化较大。
使用所有周围的预处理代码后、我仍然看到每个内核的 CPU 利用率平均高达40%。 此处的大多数多线程/过程应该是 gstreamer / CV 捕获的结果
根据我在您上一个主题中所看到的、您似乎遇到了更高的 CPU 负载和可变推理延迟。 您是否也使用 clock () API 测量了它? 我建议重新审视一下。 除此之外、您的模型可能在 CPU 上运行一些操作? 您的分辨率很小(128x128x3)、因此预处理不应该是很大的负载。
BR、 Reese