请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:TDA4AEN-Q1 Thread:TDA4VM 中讨论的其他器件
工具/软件:
tda4AEN SDK10.0:
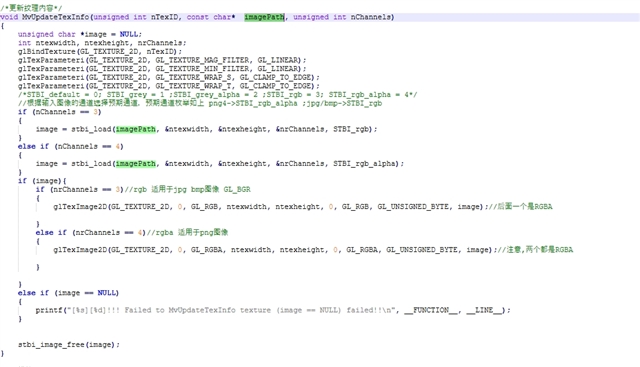
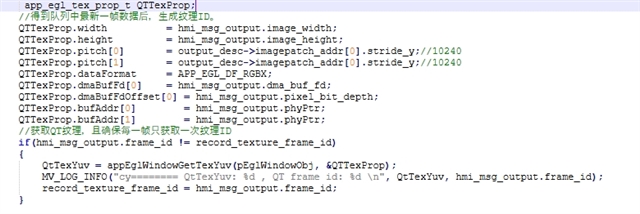
为了解决使用2560x1440层重叠更新 QT 内容时 GPU 时间增加的问题、我们当前使用共享存储器 DMA 句柄。 这涉及将图像内存对象eglCreateImageKHR与EGL_LINUX_DMA_BUF_EXT扩展名关联、并使用更新纹理内容glEGLImageTargetTexture2DOES。 虽然这种方法减少了更新期间的开销、但在使用纹理时会增加内存带宽并增加3-5ms 的延迟。
电路板端测试:
以 TDA4VM 为例测试2560x1440映像:
- A. 将共享内存 DMA
dma_fd()与eglCreateImageKHR和一起使用glEGLImageTargetTexture2DOES以生成纹理。 - b. 使用
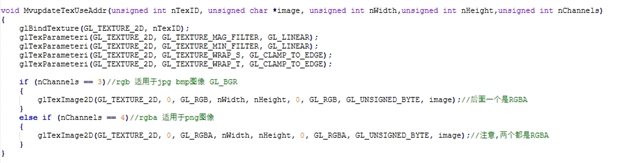
glTexImage2D生成纹理。 - 使用统一渲染接口渲染。
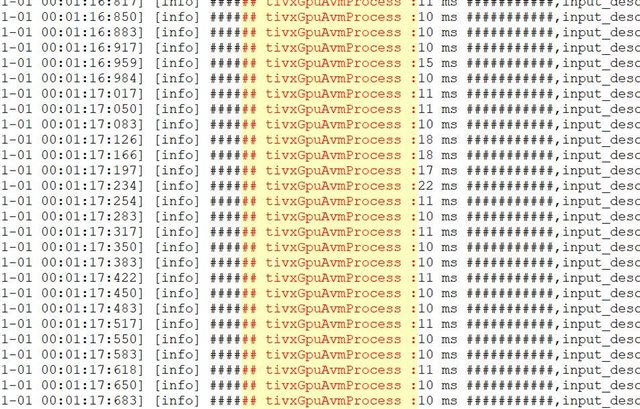
比较结果如下:
DMA_FD 方法:


使用标准glTexImage2D纹理生成方法:
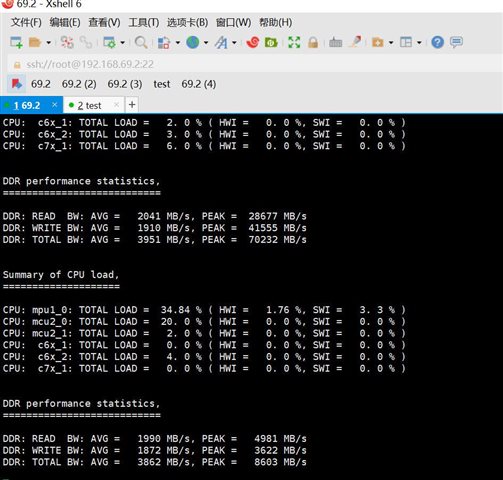
比较:
存在近似值的差异 200+ MB 额外增加 3ms dma_fd与标准glTexImage2D纹理生成方法相比、使用方法时的延迟。
我想问、问题的原因是否是使用创建映像时 EGL_LINUX_DMA_BUF_EXT,它通过 DMA 将数据从外部存储传输到 GPU 纹理,这可能会导致更高的 DDR 带宽消耗。 另一方面、 glTexImage2D是在 GPU 内创建纹理的标准方法、无需进行外部内存数据传输、从而降低了带宽消耗。 是否有任何其他因素会导致这种情况?是否有任何方法可以优化它?