

请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:TDA4VM 工具/软件:
我的 SDK 版本:RTOS 10.01.00.04
尊敬的 TI 专家:
我将根据"app_tidl_avp4"创建一个自定义应用、并进行了以下两项更改:
- 将显示输出更改为 SRV
- 将 TIDL 从 SEG 更改为 OD
这种变化导致了整个图的性能下降、现在大约为20fps。
GRAPH: custom_app_graph (#nodes = 11, #executions = 39722) NODE: CAPTURE1: capture_node: avg = 1622 usecs, min/max = 154 / 61714 usecs, #executions = 39722 NODE: VPAC_VISS1: viss_node: avg = 18505 usecs, min/max = 17735 / 24338 usecs, #executions = 39722 NODE: MCU2-0: aewb_node: avg = 455 usecs, min/max = 154 / 65242 usecs, #executions = 39722 NODE: VPAC_LDC1: ldc_node: avg = 16601 usecs, min/max = 13899 / 24016 usecs, #executions = 39722 NODE: VPAC_MSC2: scaler_node: avg = 26454 usecs, min/max = 21934 / 33801 usecs, #executions = 39722 NODE: DSP-1: PreProcNode: avg = 3554 usecs, min/max = 3328 / 4447 usecs, #executions = 39722 NODE: DSP_C7-1: tidl_node: avg = 49816 usecs, min/max = 47580 / 54819 usecs, #executions = 39722 NODE: DSP-2: DrawBoxDetectionsNode: avg = 14447 usecs, min/max = 8209 / 19117 usecs, #executions = 39722 NODE: VPAC_MSC1: mosaic_node: avg = 16820 usecs, min/max = 3871 / 84152 usecs, #executions = 39722 NODE: MPU-0: OpenGL_SRV_Node: avg = 15226 usecs, min/max = 11878 / 46502 usecs, #executions = 39722 NODE: DISPLAY1: DisplayNode: avg = 8845 usecs, min/max = 106 / 33199 usecs, #executions = 39729 PERF: FILEIO: avg = 0 usecs, min/max = 4294967295 / 0 usecs, #executions = 0 PERF: TOTAL: avg = 49885 usecs, min/max = 32556 / 74620 usecs, #executions = 17449 PERF: TOTAL: 20. 4 FPS
我认为、通过将图形分为两个、一个用于 SRV 侧、一个用于 OD 侧、我可以提高性能。(下图中的红色和蓝色区域)
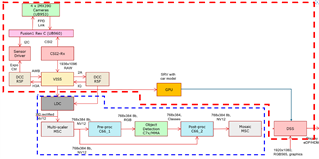
但将图形拆分为两并没有提高性能。
GRAPH: custom_app_graph1 (#nodes = 5, #executions = 296) NODE: CAPTURE1: capture_node: avg = 13394 usecs, min/max = 166 / 59766 usecs, #executions = 296 NODE: VPAC_VISS1: viss_node: avg = 19128 usecs, min/max = 17962 / 20964 usecs, #executions = 296 NODE: MCU2-0: aewb_node: avg = 310 usecs, min/max = 156 / 1371 usecs, #executions = 296 NODE: MPU-0: OpenGL_SRV_Node: avg = 11470 usecs, min/max = 10603 / 44925 usecs, #executions = 296 NODE: DISPLAY1: DisplayNode: avg = 9912 usecs, min/max = 89 / 16342 usecs, #executions = 296 GRAPH: custom_app_graph2 (#nodes = 6, #executions = 148) NODE: VPAC_LDC1: ldc_node: avg = 14735 usecs, min/max = 13905 / 15450 usecs, #executions = 148 NODE: VPAC_MSC2: scaler_node: avg = 23128 usecs, min/max = 20792 / 24294 usecs, #executions = 148 NODE: DSP-1: PreProcNode: avg = 3243 usecs, min/max = 3108 / 3427 usecs, #executions = 148 NODE: DSP_C7-1: tidl_node: avg = 45332 usecs, min/max = 41988 / 48336 usecs, #executions = 148 NODE: DSP-2: DrawBoxDetectionsNode: avg = 7428 usecs, min/max = 7023 / 13685 usecs, #executions = 151 NODE: VPAC_MSC1: mosaic_node: avg = 4696 usecs, min/max = 3857 / 29426 usecs, #executions = 151 PERF: FILEIO: avg = 0 usecs, min/max = 4294967295 / 0 usecs, #executions = 0 PERF: TOTAL: avg = 50167 usecs, min/max = 20 / 188239 usecs, #executions = 304 PERF: TOTAL: 19.93 FPS
我的目标是让 SRV 以30fps 运行、OD 以15fps 运行。 您能给我一些建议、我该如何实现这个目标吗?
此致、
Daigo
