请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:AM5728 Thread 中讨论的其他器件:SYSBIOS、
工具/软件:TI-RTOS
您好!
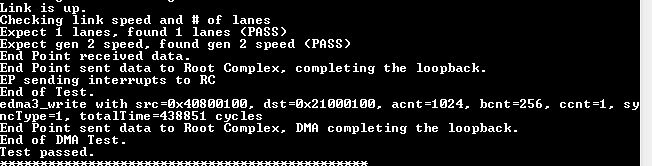
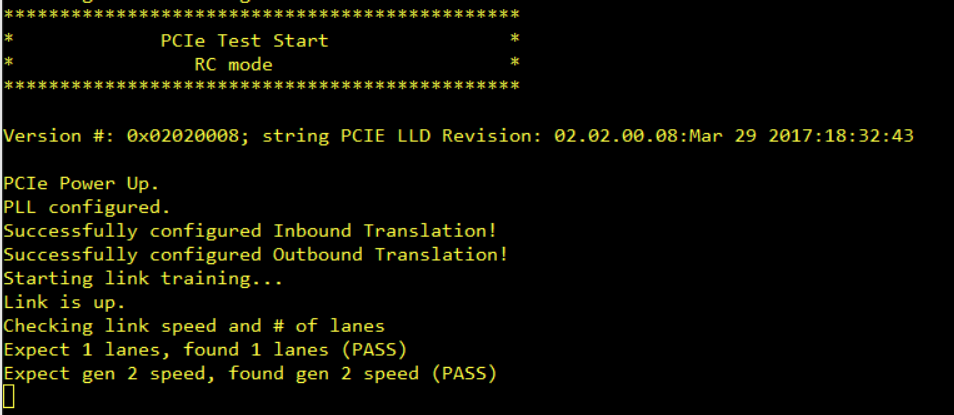
我们使用 am572x 的2个 PCIe 通道以 PCIe x2 Gen2连接的形式连接到 FPGA。 am572x 是 RC。 PCIe RC 的配置和利用是在 DSP1内核上使用带有 SYSBIOS 版本的 TI-RTOS 完成的。 6.46.0.23、EDMA LLD 版本。 2.12.1和源自 PCIe 示例驱动程序代码的 PCIe 代码。 连接可靠而稳定。 我们看到数据请求 TLPS 以64字节块的形式到达 FPGA、这是一个遗憾、因为据我所知、Sitara 应该至少有128字节。 但是、即使考虑到这些非常小的请求所产生的开销、我们也无法实现估算的带宽。
我们的测试表明、我们仅获得理论 Netto 带宽的一半左右。 如果我们仅使用一个通道、或者在两种情况下都切换到第1代而不是第2代、则带宽会下降到几乎一半、因此我们可以假设两种功能(第2代、第2代)实际上都在工作。 我们正在将 PCIe 领域的 EDMA 用于 DSP L2 RAM 或 OCMC RAM。 两者都导致 一半的理论 Netto 带宽。
我们是否可以将我们的方法与一些基准测试数据进行比较、以验证我们的发现并拒绝可能的配置问题?
最棒的
Tim