请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
https://e2e.ti.com/support/processors-group/processors/f/processors-forum/640765/am3359-cpsw-issues
器件型号:AM3359主题中讨论的其他器件:TLK110
您好!
我正在使用 ICEv2.1评估板。 我正在处理相当高的以太网流量(一个端口25 Mb/s、另一个端口5 Mb/s)、CPSW 处于双 MAC 模式、但 ALE 配置为自动将多播帧从端口 2转发到端口1。
我收到的数据包丢失*我认为*是由于端口 FIFO 溢出造成的,但我正在查看统计数据并看到一些非常奇怪的东西。
我看到冲突(单次冲突、延迟冲突、延迟 TX 帧)应该是不可能的、因为两个端口都连接在全双工链路上(一个端口连接到交换机、另一个端口连接到 PC、都是强制全双工、都报告全双工、 而 ICEv2上的两个 PHY 都报告为全双工)。
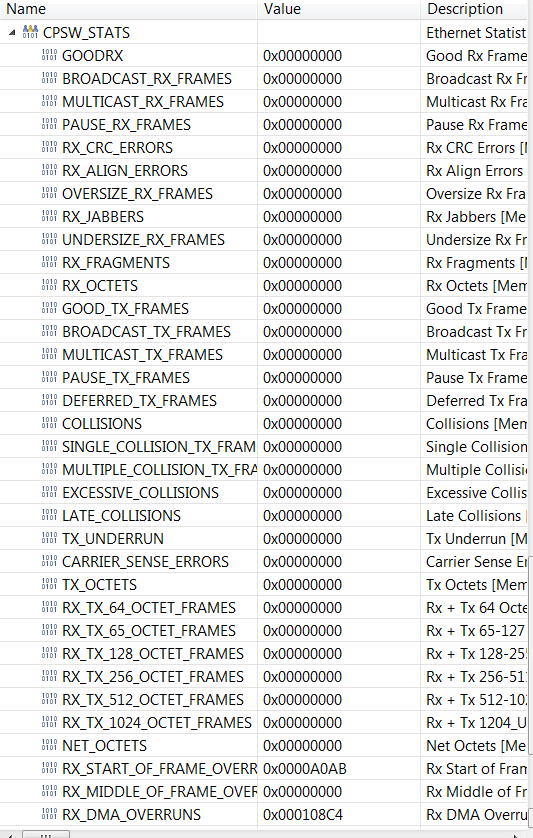
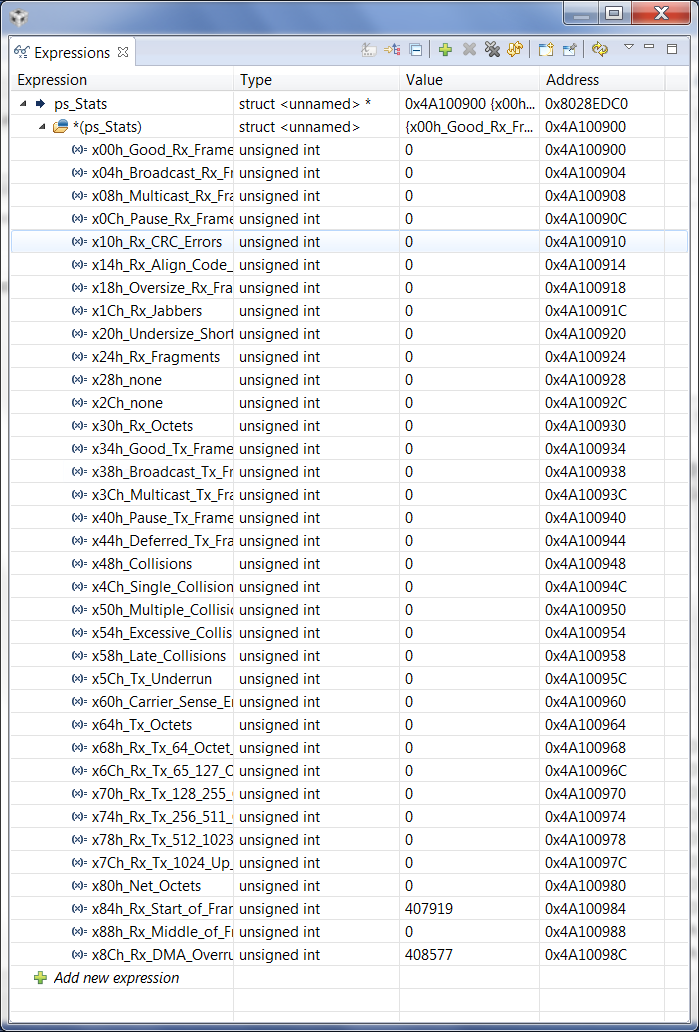
2.在端口0上,仅启用端口0统计信息,我看到许多 Rx SoF 超支和 DMA 超支,但其他统计信息都为零。 这是怎么做的? 成功接收到许多帧、因此我希望看到一些以网络八位位组表示的数据。 随附的屏幕截图。 尽管统计数据显示没有进行传输、但我成功地接收到每秒500帧的数据、我可以在 PC 上运行 Wireshark 的情况下看到这一点。
3.即使我看到 Rx SoF 和 DMA 超限、DMA 队列中始终至少有3个未使用的缓冲描述符。
我能信任统计数据吗?