请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:TDA4VH-Q1 工具与软件:
您好!
我有一个关于代码执行延迟的问题。
电路板:J784s4定制电路板
PDK 09.02.00.30
Linux
SPL 引导
拆分模式下的 R5F 主域: MCU2_1
我正在使用 Lauterbach ETM 示波器对 TDA4VH-Q1上的 R5F 进行性能评测。
当我在 A72上施加压力时、我会在 R5F (连接和未连接 JTAG 调试器)上观察到零星的停转。
我们使用的 Stress-ng 命令如下:
stress-ng --cpu-method matrixprod --matrix 0 --memcpy 4 --ioport 4 --VM 4 --vm-bytes 20%--fault 4 -- tz
和
Stress-ng --cache 8 --激进-- CPU 3.
此外、我们使用 RPMSG 和 MSMC 上的数据传输加载系统。
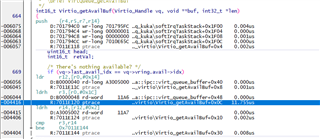
我们使用 GPIO 和 Timer12来确认延迟是否"真实"。
您有什么想法会导致超过16us 的长时间延迟? 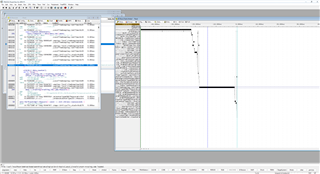
此致、
Matthias