

请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:AM62A7-Q1 主题中讨论的其他器件:AM67A、 AM68A、 TDA4VM
工具与软件:
您好!
查看 AM62A 和 TDA4EN 的比较时、我注意到 TDA4EN 支持直方图、而 AM62A 不支持直方图。 这使我相信、C7x 子系统有2个不同版本:
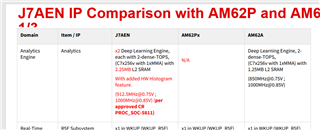
问题:
1.这些器件之间的 C7x 版本有哪些(TRM 中未提及)
2.这些版本之间还有哪些 C7x+MMA 区别?
