

Part Number: TMS320F280049C
你好,我正在尝试使用tinyml-tensorlab和NNC部署器在F280049上评估轻量时序AI分类问题的解决方案。
训练模型阶段,数据集是arc_fault_example_dsk,模型为TimeSeries_Generic_1k_t,对应yaml文件为./tinyml-tensorlab/tinyml-modelmaker/config_timeseries_classification_dsk-quant.yaml,都是使用了tensorlab的现有内容,得到了包括ONNX模型在内的许多文件输出。
1. 我注意到输出文件.\TimeSeries_Generic_1k_t\training\quantization\golden_vectors\test_vector.c中的class_0_normal set
golden_output[2] = { 0, -0, } ;,class_1_arc setgolden_output[2] = { -1, 1, } ;。而未量化.\TimeSeries_Generic_1k_t\training\base\golden_vectors\test_vector.c中的class_0_normal setgolden_output[2] = { 2, -3, } ;,class_1_arc set golden_output[2] = { -2, 4, } ;。
nnc的参数:

2. 当我把得到的ONNX模型(quantization文件夹下的那个)通过nnc部署到280049上后,其推理得到输出非常奇怪的值,它明显超出了int8t的范围: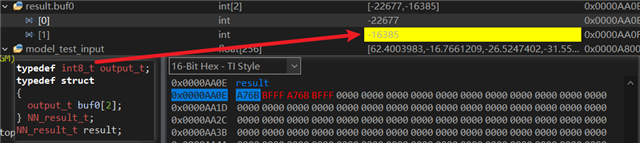
3. 我想或许是模型输出搞错了,如果把typedef直接改为float32t,则结果是两个相同的浮点值,依然与预期值差别较大:
4. 我想会不会是量化导致了精度损失,所以我又用未量化模型(base文件夹下那个)尝试,但是我遇到了memory allocation问题,__attribute__((section(".bss.noinit.tvm"), aligned(16)))
static uint8_t global_workspace[4 + 24584];,未量化模型参数太多导致无法放进一块RAMGS0:
我在尝试在syscfg中将RAMGS0~3都合并(4*8192 > 24588 ),但是完全不起作用,我不明白新版本的cmd如何修改: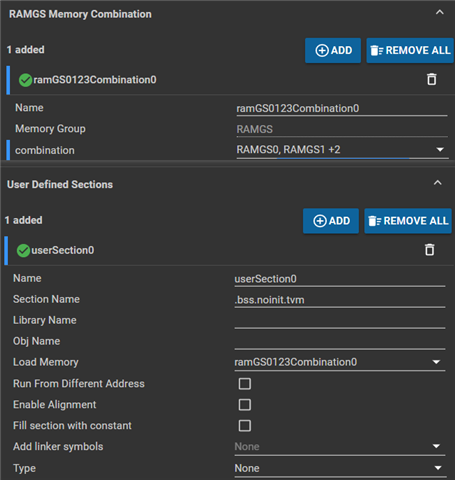
综上,我想知道:【1】期望输出的数值是否正确,是怎么看的?第几个数值大就是哪个吗?【2】【3】数值这样是不正确的,对吗?它会是量化精度损失还是其他问题?【4】如果参数超出单块RAMGS0,如何合并RAM并给“.bss.noinit.tvm”使用?
