Part Number: TMS320F28335
大家好,
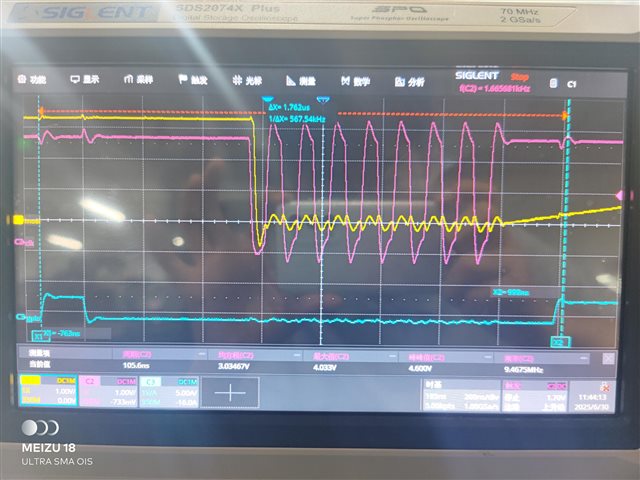
请教个关于McBSP配置成SPI后的速率问题,示波器观测了从将数据写入DXR1到总线上数据实际发送出来的时间,大概550ns的延迟,查阅手册不清楚具体延迟时间是什么导致的。
示波器图片如下,蓝色线第一个下降沿为数据写入DXR1的时刻,粉色线为MCLKXA,黄色线为MDXA ,波特率配置为9.425MHz
主要是想了解,1)延时是什么导致的?2)能否延迟,提高带宽利用率?
McBSP发送代码如下:
Uint16 McbspBSpiTxRx8Bit(Uint16 txByte)
{
Uint16 rxByte = 0U;
Uint16 i = 0U;
while((gMcbspbRegs.SPCR2.bit.XRDY == 0U) && (i < MCBSP_TIMEOUT_LOOP_CTRL_200))
{
DELAY_US(MCBSP_DELAY_TIME_100NS);
i++;
}
gMcbspbRegs.DXR1.all = txByte & 0xFFU; /* send data */
i = 0U;
while((gMcbspbRegs.SPCR1.bit.RRDY == 0U) && (i < MCBSP_TIMEOUT_LOOP_CTRL_200))
{
DELAY_US(MCBSP_DELAY_TIME_100NS);
i++;
}
rxByte = gMcbspbRegs.DRR1.all & 0xFFU; /* receive data */
return rxByte;
}
MCBSP配置代码如下:
Uint16 McbspConfig(volatile struct mcbsp_regs_t *mcbsp, const TY_SPI_CONFIG *config)
{
mcbsp->SPCR2.all = 0x0000U; /* Reset frame synchronization generator, sample rate generator, transmitter */
mcbsp->SPCR2.bit.FREE = 1U; /* debug, when a breakpoint is encountered, the transfer clock continues to run */
mcbsp->SPCR1.all = 0x0000U; /* Reset receiver, right set word, turn off digital loopback */
mcbsp->PCR.all = 0x0F08U; /* Configure as master */
mcbsp->RCR2.bit.RDATDLY = 1U; /* The data receiving delay bit is set to 1 on the master */
mcbsp->XCR2.bit.XDATDLY = 1U; /* The delay bit for sending data is set to 1 on the master */
mcbsp->SPCR1.bit.DXENA = 1U;
mcbsp->SPCR1.bit.CLKSTP = ((0xA >> 2U)& 0x03U); /* Get the second or third bit */
mcbsp->PCR.bit.CLKXP = ((0xA >> 1U) & 0x01U); /* Get the first bit */
mcbsp->PCR.bit.CLKRP = (0xA & 0x01U); /* Get the 0th bit */
mcbsp->MFFINT.bit.XINT = 0u;
mcbsp->RCR1.bit.RWDLEN1 = 0; /* Configure the word size to receive data, macros available */
mcbsp->XCR1.bit.XWDLEN1 = 0; /* Configure the word size to send data, macros available */
mcbsp->SRGR2.all = 0x2000U; /* Determine the value,CLKSM=1, frame synchronization pulse period FPER =1 CLKG period */
mcbsp->SRGR1.all = 7; /* Used to configure clock rate CLKG and CLKG cycle pulse width */
/* CLKG periodic pulse width defaults to 1 sampling period */
DELAY_US(MCBSP_DELAY_TIME_1US);
mcbsp->SPCR2.bit.GRST = 1U; /* Enable the sample rate generator */
DELAY_US(MCBSP_DELAY_TIME_1US);
mcbsp->SPCR2.bit.XRST = 1U; /* Enable sender from reset */
mcbsp->SPCR1.bit.RRST = 1U; /* Enable the receiver from reset */
mcbsp->SPCR2.bit.FRST = 1U; /* Enable frame sync generator from reset */
}