请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:LAUNCHXL-F28379D 尊敬的 TI 专家:
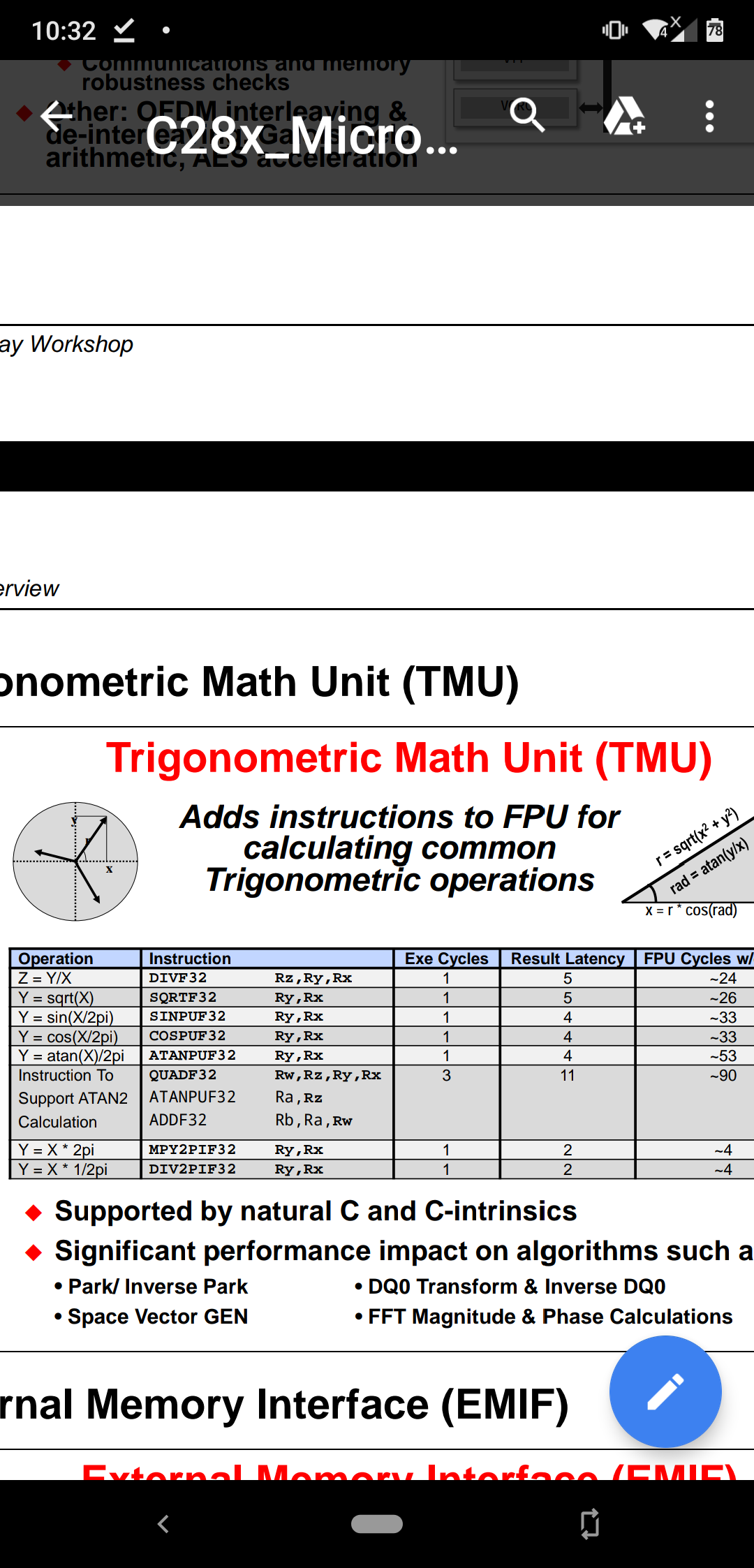
我正在使用 C2000 F28379D Launchpad。 我测试了 CPU 周期以执行"math.h"中的 asinf (float x)函数。 但结果与我预期的不符。 我认为该 LaunchPad 可能只需20到30个周期即可运行此函数、事实是它需要高达6822个 CPU 周期来处理 asinf 函数。 我已附上以下图片。