请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:SK-AM62A-LP 工具与软件:
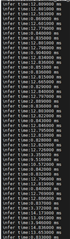
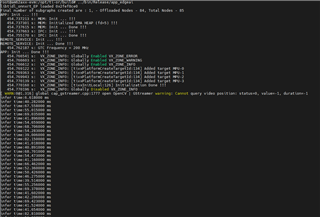
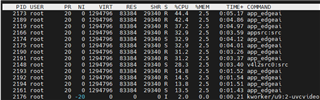
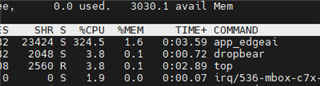
可以 根据 edgeai-gst-apps /app_cpp 同时运行 cpu+npu。 我们试图删除 allownodes.txt 的内容,并尝试 添加 这些代码后处理部分.
auto allocator_info = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);Ort::Value input_tensor_ = Ort::Value::CreateTensor<float>(allocator_info, input_image_.data(), input_image_.size(), input_shape.data(), input_shape.size());auto cpu_output = ort_session->Run(Ort::RunOptions{ nullptr }, &input_names[0], &input_tensor_, 1, output_names.data(), 1);const float* output_cpu = cpu_output[0].GetTensorMutableData<float>();但所有的 fps 将下降到 5。 这是否正常?


 。但是超过128次或是用while1到128次就直接结束了 μ A
。但是超过128次或是用while1到128次就直接结束了 μ A 
 如果我在warmup后面实现类似摄像头循环读图片再处理的效果、infertime不一致 μ A
如果我在warmup后面实现类似摄像头循环读图片再处理的效果、infertime不一致 μ A