This thread has been locked.
If you have a related question, please click the "Ask a related question" button in the top right corner. The newly created question will be automatically linked to this question.
https://e2e.ti.com/support/processors-group/processors/f/processors-forum/1450567/am6421-ospi-frame-is-split
工具与软件:
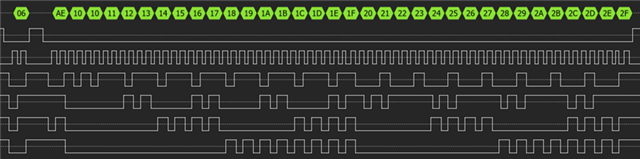
在直接模式下、时钟为10M
如上图所示调用接口、波形如下所示。
一个帧被分成三个帧。
我想知道这种现象是否正确?
尊敬的 Vaibhav:
非常感谢您的努力。
您是否可以使用以下配置再次进行测试?
时钟:100 MHz、时钟分频器:2 (或者 时钟:200 MHz、时钟分频器:4)
2. 读取512个字节
3. 测试 OSPI_readIndirect 的性能(__LW_AT__使用以下类似方法)
uint32_t cycleCountBefore, cycleCountAfter, cpuCycles; CycleCounterP_reset(); cycleCountBefore = CycleCounterP_getCount32(); OSPI_readIndirect(xx,xx,xx,xx); cycleCountAfter = CycleCounterP_getCount32(); cpuCycles = cycleCountAfter - cycleCountBefore; DebugP_log("CPU cycles:%u\n", cpuCycles);
期待您的回复。
BR
Ryan
您好、Ryan、
TAP 模式支持的模式如下:
Unknown 说:读取512字节
应该可以阅读。
Unknown 说:测试 OSPI_readIndirect 的性能(__LW_AT__使用以下类似方法)
您可以继续操作。
如果您遇到任何问题、敬请告知。
此致、
Vaibhav
我想知道您这边的测试结果(上述配置)。
我没有做时间分析,因为它不是在最初的询问发布我们昨天的电话,所以我现在要做它,并在某个时间发送给你。
下周我会根据大家提出的更改修改 SDK、并进行一次时间分析测试。
我会在测试完成后立即通知您。
请继续并计算随附 API 定义中定义的时间:
int32_t OSPI_readIndirect(OSPI_Handle handle, OSPI_Transaction *trans) { int32_t status = SystemP_SUCCESS; const OSPI_Attrs *attrs = ((OSPI_Config *)handle)->attrs; OSPI_Object *obj = ((OSPI_Config *)handle)->object; const CSL_ospi_flash_cfgRegs *pReg = (const CSL_ospi_flash_cfgRegs *)(attrs->baseAddr); uint8_t *pDst; uint32_t addrOffset; uint32_t remainingSize; uint32_t readFlag = 0U; uint32_t sramLevel = 0, readBytes = 0; uint32_t dacState; uint32_t cycleCountBefore, cycleCountAfter, cpuCycles; addrOffset = trans->addrOffset; pDst = (uint8_t *) trans->buf; /* Disable DAC Mode */ dacState = obj->isDacEnable; if(dacState == TRUE) { OSPI_disableDacMode(handle); } /* Config the Indirect Read Transfer Start Address Register */ CSL_REG32_WR(&pReg->INDIRECT_READ_XFER_START_REG, addrOffset); /* Set the Indirect Write Transfer Start Address Register */ CSL_REG32_WR(&pReg->INDIRECT_READ_XFER_NUM_BYTES_REG, trans->count); /* Set the Indirect Write Transfer Watermark Register */ CSL_REG32_WR(&pReg->INDIRECT_READ_XFER_WATERMARK_REG, CSL_OSPI_SRAM_WARERMARK_RD_LVL); CycleCounterP_reset(); cycleCountBefore = CycleCounterP_getCount32(); /* Start the indirect read transfer */ CSL_REG32_FINS(&pReg->INDIRECT_READ_XFER_CTRL_REG, OSPI_FLASH_CFG_INDIRECT_READ_XFER_CTRL_REG_START_FLD, 1); if(OSPI_TRANSFER_MODE_POLLING == obj->transferMode) { remainingSize = trans->count; while(remainingSize > 0U) { if(OSPI_waitReadSRAMLevel(pReg, &sramLevel) != 0) { /* SRAM FIFO has no data, failure */ readFlag = 1U; status = SystemP_FAILURE; trans->status = OSPI_TRANSFER_FAILED; break; } readBytes = sramLevel * CSL_OSPI_FIFO_WIDTH; readBytes = (readBytes > remainingSize) ? remainingSize : readBytes; /* Read data from FIFO */ OSPI_readFifoData(attrs->dataBaseAddr, pDst, readBytes); pDst += readBytes; remainingSize -= readBytes; } /* Wait for completion of INDAC Read */ if(readFlag == 0U && OSPI_waitIndReadComplete(pReg) != 0) { readFlag = 1U; status = SystemP_FAILURE; trans->status = OSPI_TRANSFER_FAILED; } } cycleCountAfter = CycleCounterP_getCount32(); if(cycleCountAfter > cycleCountBefore) { cpuCycles = cycleCountAfter - cycleCountBefore; } else { cpuCycles = (0xFFFFFFFFU - cycleCountBefore) + cycleCountAfter; } cpuCycles = cycleCountAfter - cycleCountBefore; DebugP_log("CPU cycles for INDAC transfer of 512 bytes is: %u \r\n", cpuCycles); /* Return to DAC mode if it was initially in enabled state */ if(dacState == TRUE) { OSPI_enableDacMode(handle); } return status; }
在 SysConfig 中、针对 OSPI 的设置如下:166 MHz、时钟分频器:4、模式:8D-8D-8D
我最后得到的值是:
" INDAC 传输512字节的 CPU 周期为:22362 "
如何将这些周期转换为一个有意义的数字?
由于 R5内核在800 MHz 下运行、因此时间(以微秒为单位)= 22362 *(1 / 800)~= 27微秒。
此致、 Vaibhav
在内部讨论之后、我将重新连接512字节的波形。 感谢您的耐心。
按照您的要求、INDAC 读取512字节的测试结果:
我有疑问。 在时钟的不同情况下、为什么时间消耗几乎相同?
尊敬的 Rayn:
512字节事务发生在 OSPI 控制器上、CPU 周期由 PMU 进行计数、 至于上下文开销 费用、我认为我们无法获得明显不同的周期计数。 希望我们能重点关注数据包 长度和重叠的问题。 谢谢。
50m 41.5M 33.3M
512B 8D-8D-8D 5.12us 60168675us 7.68us
Linjun
我非常确信、对于128字节的 INDAC 读取、可以在您的设置中看到在1个 CS 下发生的操作。
请告诉我、对于512字节 INDAC 读取、您会看到什么?
我很确定、完全没有重叠。
但芯片选择呢? 在多少芯片选择下、您会看到512字节传输?
当我读取128字节的数据时、请注意我的闪存侧配置。 当我继续读取512字节的数据时、采用相同的配置。
感谢您的努力。
目前、可以通过 INDAC 读取来解决数据包长度和重叠问题。
但是、从性能的角度来看、此模式无法满足要求。
除了传输所需的时间外、上下文开销费用太长。
是否有办法减少上下文开销费用。
我们希望将上下文开销保持在2微秒以内。
感谢您的耐心。
Unknown 说:目前、可以通过 INDAC 读取解决数据包长度和重叠的问题。
我很高兴在使用 INDAC 模式时您不会看到重叠情况。
我已经检查了波形、并且来自512字节 INDAC 传输的波形所花费的时间为:14.736微秒。
波形应该是一个很好的测量点、因为您可以通过放置两个标记(一个在传输开始时、另一个在传输结束时)来跟踪时序。
此外、该时间包括您的命令(0xEE、0xEE)+地址+数据(读回)。 因此、在检查波形时、我看到512个字节的时间是14.736微秒。 我以166 MHz 和时钟分频器4运行。
Ryan、如果您根据您看到的波形来测量时间、会很有帮助。 根据我的假设、这会更精确。 请告诉我您看到了多少微秒?
虽然根据波形测量时间是一种很好的方法、但我们更关注调用 C 函数界面前后的时间差。 这个时间对我们的业务至关重要。 我们的测试表明、通过 C 函数接口测得的时间明显大于使用波形测得的时间。
在直接模式下、额外的时间极短。 但是、如果在间接模式下、额外的时间是不可避免的、我们可能不得不放弃它。
Unknown 说:但是、如果在间接模式下不可避免额外的时间、我们可能必须放弃它。
例如,当我们进行间接传输时,我们会在 API OPSI_readIndirect ()内设置一些寄存器
您好、Vaibhav、
我期待着你的答复。
由于我们的 SDK 不会对 NOR 或 NAND 闪存执行 INDAC 读取、因此我们没有在 MCU PLUS SDK 文档中提供性能测量。
除此之外、我正在研究 DMA DAC 读取的可能性、请注意、DMA 读取的下部拷贝为1024字节、这意味着传输大小应大于1024字节、以便发生 DMA。
因此、我们可以按如下方式更改此宏:
在文件中、ospi_v0.c 将宏更改为:
此外、我知道您的驱动程序目前已配置为 readIndirect、这是我最近提出的更改。
为了确保驱动程序执行 OSPI_readDirect 操作、请遵循此处的说明: https://e2e.ti.com/support/processors-group/processors/f/processors-forum/1450567/am6421-ospi-frame-is-split/5683156#5683156
但请确保在 flash_nor_ospi.c 文件中写入 OSPI_readDirect、而不是 OSPI_readIndirect、并按照分步说明中所述重新构建库。
Ryan、您好!
该主题是关于"OSPI 帧被拆分"、很明显、可以寻址间接访问模式。 如果您对总线实时或总线效率要求有任何疑问、请提交新主题。 谢谢。
您好!
不确定是否创建了另一个专门讨论 INDAC 时序的线程。
但是、我将在这里提供更新、我已经用不同的字节数和时钟频率对 INDAC 和 DAC 进行了测量。
在与其他专家一起研究这些值之后、我将把数字放在这里。
注意:
我们通过将 OSPI_readFifoData API 放置在 TCMB0而不是 MSRAM 中来提高性能、但这也不会增加 API OSPI_readIndirect 的吞吐量。
另外还观察到、在从 FIFO 读取数据时、大部分时间都要花费、更具体地说就是 OSPI_readFifoData ()。
观察到的另一件事是、捕获的波形的时序要少得多。 那么、在读取512字节 INDAC 数据时、导线/波形上的时间就为6.9微秒、而在 OSPI_readIndirect 中、我会看到26-29微秒、其中90%的时间都被 OSPI_readFifoData ()消耗。
您好、Vaibhav
能否减少 OSPI_readFifoData 的时间消耗?
此致
Zekun
尊敬的 Zekun:
这些是在 TI EVM AM64x-SK 上看到的电流数字。
为提高效率所做的努力为:(这些努力没有提高 OSPI_readInDirect API 的效率)
I 和 Lucas 一直在对 API OSPI_readIndirect ()进行一些调整以进行一些实验。
目前已经看到了一些改善。
之前、使用166 MHz 进行512字节传输所需的时间为29-30微秒、因而带宽约为17.65Mbps。
在进行修改后、我们看到延迟仅为14-15微秒(通过在每个周期读取不同的512字节数据来运行2000个测试周期)、因此现在可以看到改善的带宽为34Mbps。
我需要一些时间来为您编写一份所需修改的正式列表、并在我稍微清理完代码后与您分享这些更改。
跟进疑问:
同时、您能否告诉我您是否始终要读取 精确到512个字节的数据? 或者您有时也可能读取小于512字节的数据?
我现在将分享这些更改。
将以下 API 替换为当前定义:
请包括:
static int32_t Flash_norOspiRead(Flash_Config *config, uint32_t offset, uint8_t *buf, uint32_t len) { int32_t status = SystemP_SUCCESS; Flash_NorOspiObject *obj = (Flash_NorOspiObject *)(config->object); Flash_Attrs *attrs = config->attrs; int32_t startTime = 0, endTime = 0; if(obj->phyEnable) { OSPI_enablePhy(obj->ospiHandle); } /* Validate address input */ if ((offset + len) > (attrs->flashSize)) { status = SystemP_FAILURE; } if (status == SystemP_SUCCESS) { OSPI_Transaction transaction; OSPI_Transaction_init(&transaction); transaction.addrOffset = offset; transaction.buf = (void *)buf; transaction.count = len; uint32_t* source = (uint32_t*) 0x60100000; CacheP_inv(source, 512, CacheP_TYPE_ALLD); startTime = ClockP_getTimeUsec(); status = OSPI_readIndirect(obj->ospiHandle, &transaction); endTime = ClockP_getTimeUsec(); DebugP_log("Time in microseconds for %u bytes indac read is %u \r\n", len, (endTime - startTime)); } if(obj->phyEnable) { OSPI_disablePhy(obj->ospiHandle); } return status; }
int32_t OSPI_readIndirect(OSPI_Handle handle, OSPI_Transaction *trans) { int32_t status = SystemP_SUCCESS; const OSPI_Attrs *attrs = ((OSPI_Config *)handle)->attrs; const CSL_ospi_flash_cfgRegs *pReg = (const CSL_ospi_flash_cfgRegs *)(attrs->baseAddr); uint8_t *pDst; uint32_t addrOffset; uint32_t sramLevel = 0; uint32_t* source = (uint32_t*) 0x60100000; addrOffset = trans->addrOffset; pDst = (uint8_t *) trans->buf; uint32_t* rxBuffer = (uint32_t*) pDst; /* Disable DAC Mode */ CSL_REG32_FINS(&pReg->CONFIG_REG, OSPI_FLASH_CFG_CONFIG_REG_ENB_DIR_ACC_CTLR_FLD, 0U); /* Config the Indirect Read Transfer Start Address Register */ CSL_REG32_WR(&pReg->INDIRECT_READ_XFER_START_REG, addrOffset); CSL_REG32_WR(&pReg->IND_AHB_ADDR_TRIGGER_REG, 0x100000); // set INDIRECT_TRIGGER_ADDR_RANGE_REG to 7 instead of 4 CSL_REG32_WR(&pReg->INDIRECT_TRIGGER_ADDR_RANGE_REG, 7); /* Set the transaction count */ CSL_REG32_WR(&pReg->INDIRECT_READ_XFER_NUM_BYTES_REG, trans->count); // set parition config reg value to 127 imstead of the default 63 CSL_REG32_WR(&pReg->SRAM_PARTITION_CFG_REG, 127); /* Set the Indirect Write Transfer Watermark Register */ CSL_REG32_WR(&pReg->INDIRECT_READ_XFER_WATERMARK_REG, 32); /* Start the indirect read transfer */ CSL_REG32_FINS(&pReg->INDIRECT_READ_XFER_CTRL_REG, OSPI_FLASH_CFG_INDIRECT_READ_XFER_CTRL_REG_START_FLD, 1); // checking if indirect read has been completed. do{ OSPI_waitReadSRAMLevel(pReg, &sramLevel); }while(sramLevel != 128); for(int i = 0; i < 128; i += 8) { rxBuffer[i + 0] = source[i + 0]; rxBuffer[i + 1] = source[i + 1]; rxBuffer[i + 2] = source[i + 2]; rxBuffer[i + 3] = source[i + 3]; rxBuffer[i + 4] = source[i + 4]; rxBuffer[i + 5] = source[i + 5]; rxBuffer[i + 6] = source[i + 6]; rxBuffer[i + 7] = source[i + 7]; } // reset INDIRECT_TRIGGER_ADDR_RANGE_REG to 4 instead of 7 CSL_REG32_WR(&pReg->IND_AHB_ADDR_TRIGGER_REG, 0x00); CSL_REG32_WR(&pReg->INDIRECT_TRIGGER_ADDR_RANGE_REG, 4); // partition config reg CSL_REG32_WR(&pReg->SRAM_PARTITION_CFG_REG, 63); /* Set the Indirect Write Transfer Watermark Register back to default 16 */ CSL_REG32_WR(&pReg->INDIRECT_READ_XFER_WATERMARK_REG, 16); return status; }
此外、确保在应用程序的 SysConfig 中包含以下设置:
请注意、在上一个屏幕截图中、 .data.gOspiRxBuf 是接收缓冲区、我在应用程序级别全局初始化、如下所示:
此外、我的设置是166 MHz / 4、并且未像我们执行 INDAC 读取时那样启用 PHY 模式。
另请注意、OSPI_readIndirect 内部的实现专门满足512字节读取的需求。 可以将其修改 为通用、以读取 x 个字节。 首先、如果您也看到与我相同的性能、请通过在您的设置中读取精确的512字节来让我知道。
根据今天在每周会议上的讨论、将其标记为已解决。
Ashwani
我假设每周会议中已经讨论过这个问题、并且您的目标已经在提高吞吐量性能方面得到实现。
Ashwani 根据我猜的电话中他的输入将线程标记为关闭。
如果您还需要了解其他信息、请告知我。