请注意,本文内容源自机器翻译,可能存在语法或其它翻译错误,仅供参考。如需获取准确内容,请参阅链接中的英语原文或自行翻译。
器件型号:MSP430FR6043 主题中讨论的其他器件:MSP430WARE
创建了一个测试、该测试使用正常的乘法/除法填充256个浮点值、然后使用 IQ20使用相应的 IqmathLib 运算来填充另256个阵列、其中:
- -mlarge
- -mcode-region=任意一种
- -mdata-region=none
- C:\ti\msp430ware_3_80_14_01\iqmathlib\libraries\ccs\MPY32\5xx_6xx\IQmathLib_CCS_MPY32_5xx_6xx_cpux_large_code_large_data.lib
前2个选项(-mload 和-mcode-region=any)是必须的、因为我们需要低 FRAM 和 HIFRAM。 最后一个是不幸的(_LARGE_DATA.lib)、但这只是看起来使用 GCC 进行编译并且指定了内存要求(请参阅)。
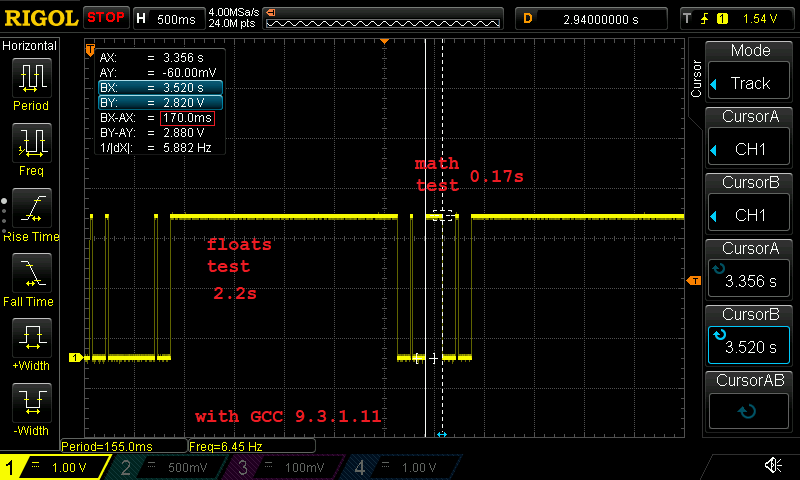
浮点值和数学填充值由调试 LED 围绕并在示波器上进行跟踪:
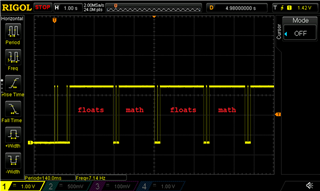
结果也并不乐观:
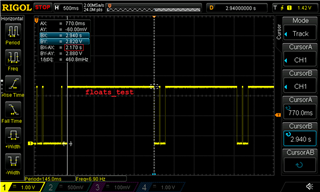
- 2.17s、正常浮点操作:
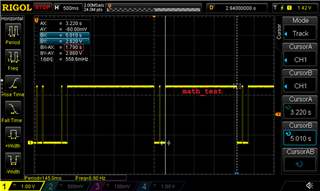
- IqmathLib 操作仅支持1.79s:
此外、当尝试将 IqmathLib 结果转换为 float (使用_IQ20toF)以与实数 float 值进行比较时、代码不再起作用、甚至调试会话在刷写后会立即卡住:
如上所述、似乎是一个限值? 到247时、项目仍然可以工作、也可以调试、而使用248或以上版本时、不再需要。 247/248构建之间的映射差异未显示任何特殊情况来损坏代码:
随附测试项目。
e2e.ti.com/.../test_5F00_GCC.zip
非常感谢您提供帮助或建议!
丹尼尔